Registration
We welcome the researchers and students who are interested in AI reasoning and decision-making to join us! To receive relevant workshop information in time, please click the following link to register.
Speakers
-
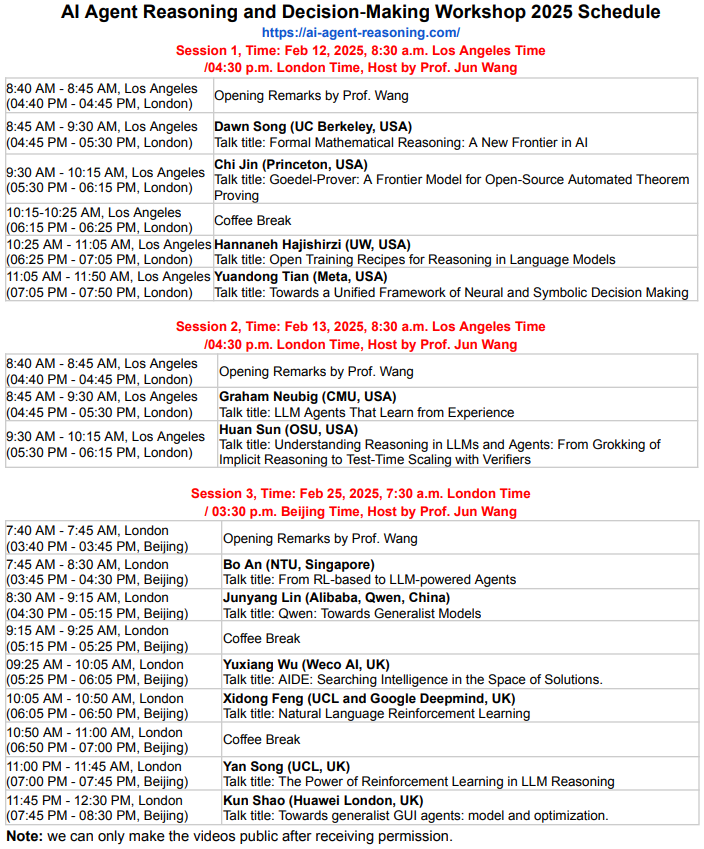
Yuandong Tian. Yuandong Tian is a Research Scientist Director in Meta GenAI, leading a group for Llama reasoning. His research direction covers multiple aspects of decision making, including reinforcement learning, planning and efficiency, as well as theoretical understanding of LLMs. He is the project lead for OpenGo project, an efficient replicate of AlphaZero that beats professional players with a single GPU during inference, serves as the main mentor of StreamingLLM and GaLore that improve the training and inference of LLM, and is the first-author recipient of 2021 ICML Outstanding Paper Honorable Mentions and 2013 ICCV Marr Prize Honorable Mentions, and also received the 2022 CGO Distinguished Paper Award. Prior to that, he worked in Google Self-driving Car team in 2013-2014 and received a Ph.D in Robotics Institute, Carnegie Mellon University in 2013. He has been appointed as area chairs for NeurIPS, ICML, AAAI, CVPR and AIStats.
- Talk Title: Towards a unified framework of Neural and Symbolic Decision Making.
- Talk Abstract: Large Language Models (LLMs) have made impressive achievement while still struggling with complex tasks that require advanced decision-making done by reasoning, planning and optimization. While longer chains-of-thoughts are used in SoTA systems and work better, such system still cannot achieve the performance of traditional symbolic solvers which provide precise, guaranteed solutions to well-defined problems. Two research opportunities emerge: first, how to leverage the strengths of both by integrating neural and symbolic components into one system, and second, how to understand why the two kinds of systems have such distinct natures and whether there is a way to unite them from the first principles. In this talk, we will discuss our published works on both sides.
- Talk Video:
-
Dawn Song. Dawn Song is a Professor in Computer Science at UC Berkeley and Co-Director of Berkeley Center on Responsible Decentralized Intelligence. Her research interest lies in AI and deep learning, security and privacy, and decentralization technology. She is the recipient of various awards including the MacArthur Fellowship, the Guggenheim Fellowship, the NSF CAREER Award, the Alfred P. Sloan Research Fellowship, the MIT Technology Review TR-35 Award, ACM SIGSAC Outstanding Innovation Award, and more than 10 Test-of-Time Awards and Best Paper Awards from top conferences in Computer Security and Deep Learning. She has been recognized as Most Influential Scholar (AMiner Award), for being the most cited scholar in computer security. She is an ACM Fellow and an IEEE Fellow. She obtained her Ph.D. degree from UC Berkeley. She is also a serial entrepreneur and has been named on the Female Founder 100 List by Inc. and Wired25 List of Innovators.
- Talk Title: Formal Mathematical Reasoning: A New Frontier in AI.
- Talk Video:
-
Hannaneh Hajishirzi. Hanna Hajishirzi is the Torode Family Associate Professor in the Allen School of Computer Science and Engineering at the University of Washington and a Senior Director of NLP at AI2. Her current research delves into various domains within Natural Language Processing (NLP) and Artificial Intelligence (AI), with a particular emphasis on accelerating the science of language modeling, broadening their scope, and enhancing their applicability and usefulness for human lives. She has published over 140 scientific articles in prestigious journals and conferences across ML, AI, NLP, and Computer Vision. She is the recipient of numerous awards, including the Sloan Fellowship, NSF CAREER Award, Intel Rising Star Award, Allen Distinguished Investigator Award, Academic Achievement UIUC Alumni Award, and Innovator of the Year Award by GeekWire. The work from her lab has been nominated for or has received best paper awards at various conferences and has been featured in numerous magazines and newspapers.
- Talk Title: Open Training Recipes for Reasoning in Language Models.
- Talk Abstract: In this talk, I will present my team's efforts in training language models to develop reasoning capabilities. Specifically, I will discuss how we built Tulu 3, a state-of-the-art post-trained language model that surpasses DeepSeek V3 and GPT-4o. I will outline our comprehensive, open training recipe, covering data curation, supervised fine-tuning, preference tuning, and our innovative reinforcement learning method with verifiable rewards (RLVR).
- Talk Video:
-
Bo An. Bo An is a President's Chair Professor and Head of Division of Artificial Intelligence at the College of Computing and Data Science of the Nanyang Technological University (NTU). He is also Director for Centre of AI-for-X of NTU. He was a Nanyang Assistant Professor during 2014-2018. Prior to join NTU in 2013, he spent one year as an Associate Professor at the Institute of Computing Technology of the Chinese Academy of Sciences. During October 2010 to June 2012, he was a Postdoctoral Researcher at the University of Southern California, working with Professor Milind Tambe. He received the Ph.D degree in Computer Science from the University of Massachusetts, Amherst, where he was advised by Professor Victor Lesser. His research interests include artificial intelligence, multi-agent systems, computational game theory, reinforcement learning, automated negotiation, and optimization. He has published over 150 referred papers at top conferences (AAMAS, IJCAI, AAAI, ICML, NeurIPS, ICLR, KDD, ICAPS, EC, UAI, AISTATS, and WWW) and journals (JAAMAS, AIJ and ACM/IEEE Transactions). His work on applying game theory to security has been applied to develop game-theoretic randomization software that is currently deployed by the United States Federal Air Marshals Service, the United States Coast Guard, and wildlife conservation organizations. He has served as program committee members for many top conferences and was co-chair for some key international conferences/symposia. He was named to IEEE Intelligent Systems' "AI's 10 to Watch" list for 2018. He is a member of the editorial board of Journal of Artificial Intelligence Research (JAIR) and the Associate Editor of Artificial Intelligence Journal (AIJ), Journal of Autonomous Agents and Multi-agent Systems (JAAMAS), IEEE Intelligent Systems, ACM Transactions on Intelligent Systems and Technology, and ACM Transactions on Autonomous and Adaptive Systems. He was elected to the board of directors of IFAAMAS, senior member of AAAI, and ACM Distinguished Member. He was PC Co-Chair of AAMAS'20 and General Co-Chair of AAMAS'23. He will be PC Chair of IJCAI'27.
- Talk Title: From RL-based to LLM-powered Agents.
- Talk Abstract: In the early days of tackling AI problems involving complex cooperation and strategic interactions, reinforcement learning has proven effective in learning efficient policies for large-scale optimization problems that are beyond the scalability of traditional algorithmic approaches. Recently, the use of large language models (LLMs) as computational engines has given rise to a new paradigm: LLM-powered agents capable of addressing complex problems across various domains. This talk will explore our recent work within these paradigms and offer insights into the development of scalable, efficient, and distributed artificial general intelligence.
-
Graham Neubig. Graham Neubig is an Associate Professor at the Carnegie Mellon University Language Technology Institute in the School of Computer Science, and work with a bunch of great students in the lab NeuLab. His is also a chief scientist at All Hands AI, where AI agents are built for software development. His research focuses on machine learning and natural language processing. In particular, his is interested in basic research and applications of large language models, with a particular focus on question answering, code generation, multilingual processing, and evaluation/interpretability.
- Talk Title: LLM Agents that Learn from Experience.
- Talk Abstract: In this talk I will discuss how LLM agents can learn from their past experiences, specifically in the context of web agents. Specifically, I will discuss two different varieties of methods to do so. First, I will discuss agent workflow memory, an online learning method that takes the agent's past experiences and references them in future tasks. Second, I will discuss methods of using and inducing APIs in agent-based learning, demonstrating that agents with APIs can outperform those who perform web tasks directly, and discuss methods of inducing reusable APIs from past experiences.
-
Chi Jin.Chi Jin is an assistant professor at the Electrical and Computer Engineering department of Princeton University. He obtained his PhD degree in Computer Science at University of California, Berkeley, advised by Michael I. Jordan. His research primarily focuses on theoretical machine learning, particularly nonconvex optimization and reinforcement learning (RL), with recent interests extending to LLM reasoning and agents. In nonconvex optimization, he provided the first proof showing that first-order algorithm (stochastic gradient descent) is capable of escaping saddle points efficiently. In RL, he provided the first efficient learning guarantees for Q-learning and least-squares value iteration algorithms when exploration is necessary. His works also lay the theoretical foundation for RL with function approximation, multi-agency and partial observability. He is the recipient of NSF CAREER award and Sloan fellowship.
- Talk Title: Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving.
- Talk Abstract: We introduce Goedel-Prover, an open-source Large Language Model (LLM) that achieves the state-of-the-art performance in automated formal proof generation for mathematical problems. A key challenge in training LLMs for formal reasoning is the scarcity of formal data. To address this, we train formalizers to translate a substantial corpus of mathematical problems from natural language into formal language (Lean 4) in various styles, producing 1.64 million syntactically correct and content-accurate formal statements. We then train a prover iteratively, alternating between generating verified proofs from statements and refining the model using these proofs. Our model outperforms all existing open-source models for whole-proof generation across multiple benchmarks. On the miniF2F benchmark (Pass@32), our model attains a 57.6% success rate, surpassing the previous best open-source model by 7.6%. On PutnamBench, it successfully solves 7 problems (Pass@512), ranking first on the leaderboard. Furthermore, it generates 29.7K formal proofs for Lean Workbook problems, nearly doubling the 15.7K produced by earlier works.
- Talk Video:
-
Junyang Lin. Junyang Lin, a senior staff engineer at Alibaba, currently serves as the tech lead for Qwen. His research areas include natural language processing and multi-modal representation learning, with a particular focus on large-scale foundation models. He has published papers in top-tier conferences such as NeurIPS, ICML, and ACL, and his Google Scholar citation count exceeds 9,700. Since 2023, he has primarily been responsible for the development, open-sourcing, and application of the Qwen series of large models. The models he has developed include the large language model Qwen2.5, the vision-language large model Qwen2-VL, the speech-language large model Qwen2-Audio, the code large model Qwen2.5-Coder, and the math large model Qwen2.5-Math. He is dedicated to promoting the open-source availability of large models. Currently, the Qwen series of models has been downloaded over 100 million times globally, with 87,000 derivative models created based on Qwen and more than 8 million developers worldwide.
- Talk Title: Qwen: Towards Generalist Models.
- Talk Abstract: Since Alibaba launched the Qwen series of large models in 2023, the Qwen series of large language models and multimodal large models have been continuously updated and improved. This presentation will introduce the latest developments in the Qwen series of models, including the current performance and technical implementation behind the large language models Qwen2.5, the mathematical large models Qwen2.5-Math, the coding large models Qwen2.5-Coder, the vision-language large models Qwen2-VL, and the speech-language large models Qwen2-Audio, etc. Additionally, this presentation will also cover the future development directions of the Qwen series.
-
Huan Sun. Huan Sun is an endowed College of Engineering Innovation Scholar and associate professor in the Department of Computer Science and Engineering at The Ohio State University. Her research interests lie in natural language processing and artificial intelligence, especially building and benchmarking LLMs and agents and mitigating their safety risks. Huan received Best Paper Finalist at CVPR’24, Honorable Mentions for Best Paper Awards at ACL’23 (two papers), 2022 ACM SIGMOD Research Highlight Award, Best Paper Award at BIBM’21, Google Research Scholar and Google Faculty Award, NSF CAREER Award, OSU Lumley Research Award, and SIGKDD Ph.D. Dissertation Runner-Up Award, among others. Her team won third place in the first Alexa Prize TaskBot challenge in 2022. Huan received her Ph.D. from the University of California, Santa Barbara and B.S. from the University of Science and Technology of China.
- Talk Title: Understanding Reasoning in LLMs and Agents: From Grokking of Implicit Reasoning to Test-Time Scaling with Verifiers.
- Talk Abstract: The past two years have seen language agents emerge as powerful AI systems, driven by advances in large language and multimodal models. This talk presents our recent work on web agents and agents for science, showcasing the potential of cutting-edge models like OpenAI o1 and DeepSeek R1. A critical factor enabling these agents lies in the “reasoning” capabilities of LLMs -- yet fundamental questions about LLM/agent reasoning remain unanswered: (1) As the backbone model architecture, how promising or limited is Transformer for implicit multi-step reasoning? (2) During test-time scaling, under what conditions do tree search and iterative correction methods outperform simpler approaches? In the second part of this talk, I will discuss some findings from our recent work that can partly answer these questions: (1) After a "grokking" phase, transformers exhibit varying degrees of generalization across different reasoning tasks, as demonstrated through rigorous controlled experiments; (2) For test-time scaling, tree search and iterative correction require highly accurate verifiers (~90% accuracy) to outperform simpler re-ranking methods.
-
Yuxiang Wu. Yuxiang Wu is the co-founder and CTO of Weco AI, where he leads efforts to build AI agents that automate scientific discovery. His research focuses on AI agents, open-domain question answering, data generation, and knowledge-augmented pre-trained language models, and his work has been cited over 4,000 times. He has received multiple honors, including the Best Paper Award at AKBC 2020, first place in the NeurIPS 2020 EfficientQA Competition, and the Best Poster Award at the ENLSP Workshop during NeurIPS 2022.
- Talk Title: AIDE: Searching Intelligence in the Space of Solutions.
- Talk Abstract: AI-Driven Exploration (AIDE) is a reasoning-centric agent powered by large language models (LLMs) that tackles the iterative and often uncertain process of machine learning engineering as a structured decision-making problem. By framing model development as code optimization and representing trial-and-error as a tree search over potential solutions, AIDE systematically explores and refines promising avenues. This approach enables it to autonomously handle the complexity and uncertainty inherent in real-world ML design, adaptively allocating computational resources to generate stronger outcomes. Moreover, AIDE’s tree-search formulation fosters interpretability and transparency of decision steps, aligning with the workshop’s emphasis on ethical and robust reasoning. Our results demonstrate state-of-the-art performance on multiple benchmarks—including Kaggle evaluations, OpenAI’s MLE-Bench, and METR’s RE-Bench—illustrating how an agent-driven paradigm can elevate the efficiency, reliability, and accountability of AI-powered decision-making.
-
Xidong Feng. Xidong Feng is a research scientist at Google DeepMind Discovery Team. His research spans over Reinforcement Learning and generative model. He has published over 10 papers in top AI conferences or journals like NeurIPS, ICML and JMLR. He obtained his Ph.D. at Computer Science, University College London, advised by Prof. Jun Wang.
- Talk Title: Natural Language Reinforcement Learning.
- Talk Abstract: Recent breakthroughs—exemplified by OpenAI’s O1 and DeepSeek’s R1—have showcased the impressive capabilities of reinforcement learning (RL) in training large language models (LLMs). In this talk, we will review these successes and explore potential challenges and limitations in current RL for LLM paradigm. We will explore a new possibility, Natural Language Reinforcement Learning (NLRL), by extending traditional MDP to natural language-based representation space. Specifically, NLRL innovatively redefines RL principles, including task objectives, policy, value function, Bellman equation, and policy iteration, into their language counterparts. With recent advancements in large language models (LLMs), NLRL can be practically implemented to achieve RL-like policy and value improvement by either pure prompting or gradient-based training.
-
Yan Song. Yan Song is a first-year PhD student at University College London whose research focuses on reinforcement learning, multi-agent systems, and language models. He contributed to the development of OpenR—an open-source framework that leverages reinforcement learning to enhance reasoning in large language models. Yan has also organised several multi-agent AI competitions at academic conferences such as IJCAI, AAMAS, and CoG, and his work has been published in top-tier venues including ICLR, IJCAI, and AAMAS.
- Talk Title: The Power of Reinforcement Learning in LLM Reasoning.
- Talk Abstract: The recent release of DeepSeek-R1 has drawn significant attention to the use of reinforcement learning in LLM reasoning. Despite these promising advances, the full potential of reinforcement learning in language tasks has yet been fully studied. In this talk, we will review key research contributions and explore promising directions for future work.
-
Kun Shao. Kun Shao is a Principal Research Scientist and Project Manager at Huawei London Research Center. Before joining Huawei, Kun Shao received a Ph.D. degree from the Institute of Automation, Chinese Academy of Sciences. He has received several awards and has published several papers in top conferences. His main research interests are AI agents, reinforcement learning, and multi-agent systems. He has also contributed to the application of machine learning to mobile phones, robotics, autonomous driving, and game AI.
- Talk Title: Towards generalist GUI agents: model and optimization.
- Talk Abstract: GUI agents are responsible for operating devices to fulfill user requests, enabling antonomous interactions. To achieve Generalist GUI Agents, we propose a new generation of methods to achieve 1) Comprehensive Benchmarking; 2) Lightweight Model; and 3) Efficient Optimization. In this talk, we will present SPA-BENCH, a comprehensive SmartPhone Agent Benchmark designed to evaluate (M)LLM-based agents in an interactive environment that simulates real-world conditions. Then, to address the computational constraints inherent to smartphones, we introduce a lightweight Action Transformer (AcT) integrated with a fine-tuned VLM for real-time decision-making. Finally, we will introduces DistRL and VSC-RL, the novel frameworks designed to enhance the efficiency of online RL fine-tuning for GUI agents.












Workshop Organizers

Professor, University College London
Professor, Nanyang Technological University
Research Scientist Director, Meta GenAI.

Assistant Professor, University of Liverpool

Assistant Professor, Shanghai Tech

Postdoc, UC Berkeley
Copyright © 2025 Template by Inovatik